1.1 初识MySQL
1.1.1 概念
MySQL 是最流行的关系型数据库管理系统,在 WEB 应用方面 MySQL 是最好的 RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。
1.1.2什么是数据库?
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库。
每个数据库都有一个或多个不同的 API 用于创建,访问,管理,搜索和复制所保存的数据。
我们也可以将数据存储在文件中,但是在文件中读写数据速度相对较慢。
所以,现在我们使用关系型数据库管理系统(RDBMS)来存储和管理大数据量。所谓的关系型数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。
RDBMS 即关系数据库管理系统(Relational Database Management System)的特点:
- 1.数据以表格的形式出现
- 2.每行为各种记录名称
- 3.每列为记录名称所对应的数据域
- 4.许多的行和列组成一张表单
- 5.若干的表单组成database
1.2.3 RDBMS 术语
在我们开始学习MySQL 数据库前,让我们先了解下RDBMS的一些术语:
- 数据库: 数据库是一些关联表的集合。
- 数据表: 表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
- 列: 一列(数据元素) 包含了相同类型的数据, 例如邮政编码的数据。
- 行:一行(=元组,或记录)是一组相关的数据,例如一条用户订阅的数据。
- 冗余:存储两倍数据,冗余降低了性能,但提高了数据的安全性。
- 主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
- 外键:外键用于关联两个表。
- 复合键:复合键(组合键)将多个列作为一个索引键,一般用于复合索引。
- 索引:使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书籍的目录。
- 参照完整性: 参照的完整性要求关系中不允许引用不存在的实体。与实体完整性是关系模型必须满足的完整性约束条件,目的是保证数据的一致性。
1.1.4 数据库设计范式
1F:原子约束,保证原子性,每列不可再分。
2F:保证唯一:即为主键,保证表中的每列和主键相关
3F:保证没有冗余数据,保证表中的每列和主键直接相关
数据库引擎
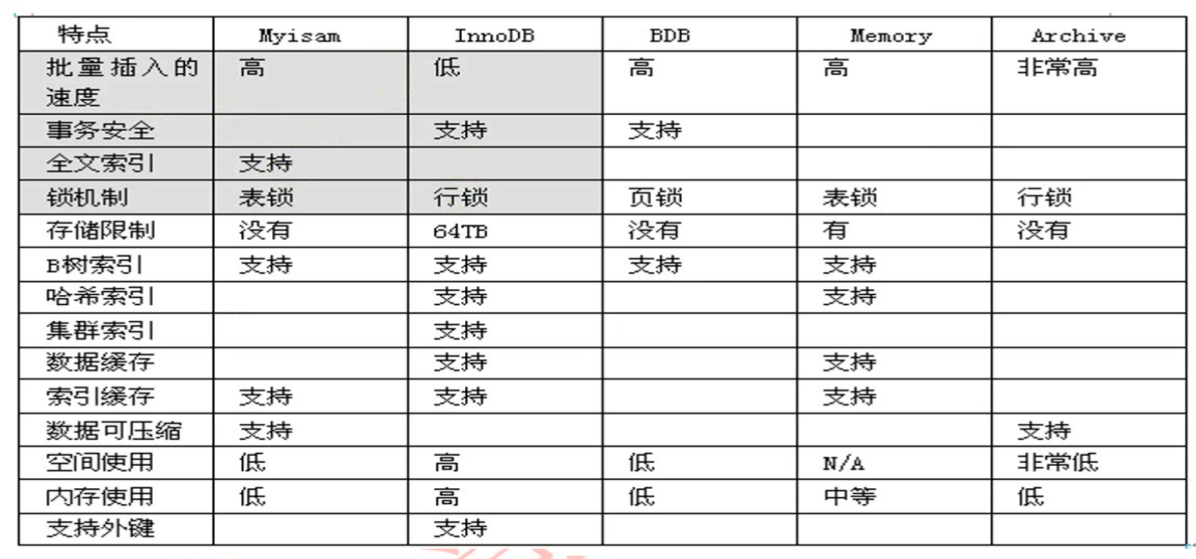
innoDB为主流引擎(事务机制)
- Myisam注意事项
定时进行碎片整理optimize table 表名
1.1.5 MySQL语法
DDL:
- 连接数据库
mysql -uroot -p
- 查看数据库列表
show datebases
- 创建数据库
1 | create datebase 数据库名( |
- 删除数据库
detele datebase 数据库名
- 修改数据库
alter datebase 数据库名
DML:
- 插入语句
insert into 表名(列名,…)values(值1,…);
- 修改语句
update 表名 set 列=新值,列=新值,…where 筛选条件;
- 删除语句
1 | create datebase 数据库名( |
- 删除数据库
detele datebase 数据库名
- 修改数据库
delete from 表名 where 筛选条件
delete 表1的别名,表2的别名 from 表1 别名,表2 别名 where 连接条件 and 筛选条件;
- 清空数据
truncate table 表名;
delete PK truncate 【常见一大面试题😈】
delete 可以加 where 条件,truncate 不能加
truncate 删除,,效率高一丢丢
假如要删除的表中有自增长列,如果用delete 删除后,再插入数据,自增长列的值从断点开始, 而truncate 删除后,再插入数据,自增长列的值从1开始。
truncate 删除没有返回值,delete 删除有返回值
truncate 删除不能回滚,delete删除可以回滚。
DQL:
- 消除重复元素
select distinct 列名 from 表名;
- 算术运算
select 列名1*列名2 as 乘积 from 表名 where 条件;
- 比较运算符
select 列名1 from 表名 where 列名>值;
- 逻辑运算符(and、or、not)
select 列名1 from 表名 where 列名>值 and 列名2<值;
- 范围和集合
select 列名1 from 表名 where 列名between minValue And maxValue;
select 列名1 from 表名 where 列名 in(值1,值2...);
- 模糊查询
select 列名1 from 表名 where 列名 like "%x%";
- 结果排序(ASC、DESC)
select 列名1 from 表名 where 列名 like "%x%" order by ASC;
- 分组查询
select 列名1 ,列名2 from 表名 group by 列名1;
- 按格式输(CONCAT)
1 | `select concat("乘积为:",列名1*列名2)from 表名 where 条件;` |
1.1.6 MySQL的优化
慢查询:顾名思义,执行很慢的查询。有多慢?超过long_query_time参数设定的时间阈值(默认10s),就被认为是慢的,是需要优化的。慢查询被记录在慢查询日志里。慢查询日志默认是不开启的。
- 查询语句
show status like 'slow_queries' - 使用执行计划explain xxx(需要调优的sql)
- 查询出信息有10列
id:为每个select语句分配唯一标识,越大优先级越高,相同则按上下顺序,为null则是结果集
select_type:区别普通查询、子查询等
table:查询的表
type:
- system:空表或表中只有一个数据
- constant:使用了唯一索引
- eq_ref:连接字段为逐渐或唯一索引
- ref:针对非唯一索引,使用等着查询非主键,或使用了最左前缀原则索引的查询
- all:全表
possible_key
key
key_len
ref
rows
extra
- 查询出信息有10列
如何将慢查询定位到日志中:
进入mysql目录,打开my.ini文件找到日志文件位置(datadir=”路径”)
停止MySQL服务
安全模式启动MySQL(mysql.exe –safe mode –slow-query-log)
查看日志文件即可查看慢查询的语句
如何实现优化:
数据库表设计(减少冗余量)合理(3F)
添加索引
分库分表技术
读写分离
配置MySQL最大连接数
MySQL服务器升级
随时清理碎片化
sql语句调优
主从复制
1.1.6 .1索引
概述:使用索引的顺序就是建索引的顺序。直到遇到范围查询后,索引失效。
优势:降低数据IO成本,提高查询效率
通过索引对数据进行排序,降低CPU消耗,order by语句效率高
where 索引列,在存储引擎层处理,索引下推ICP
select字段全是索引,即覆盖索引
劣势:空间换时间,占用空间更大,插入更新时涉及索引文件的更新,速度降低。
分类:
主键索引(pramarykey)
普通索引(
create index 索引名 on 表名)唯一索引(unique)
组合索引(
create index 索引名(字段1,字段2) on 表名)- 最左前缀原则,带头大哥不能死,中间连续不能断
全文索引(FULL_TEXT)
实现底层原理:二叉树,折半查找(选个中间值,左小右大),最多可以找到2*n
缺点:每次增删数据会更新索引文件
哪些字段可以加:
- 查询次数较多,且较多值不同的
- ps:
- 组合索引第一个条件必须使用
- 不要使用like “%x%”, 可去掉第一个%后使用
- 使用or时,条件必须都是索引
- 判断为空使用is null,而不是==null
- group by不使用索引
- 分组需要效率高可以禁用排序,
order by null - 不使用<>=
- 不使用in notin
- ps:
1.1.6 .2分库分表
1.分库:顾名思义,将一个数据库分为多个库,为垂直拆分,适用于分布式场景,将原来耦合性强的系统拆分为多个弱耦合服务。
- ps:未解决单表数据量大的问题
2.分表:顾名思义,将一个数据表分为多个表,为水平拆分,典型的有水平取模(分几张则对当前数据取模为几)算法
- ps:不好分页查询,查询受到限制
1.1.6 .3读写分离
可使用mycat进行MySQL的读写分离操作
- 好处:分摊服务器压力,提高IO性能。
- mycat中间件可以不暴露IP地址,提高安全系数
Mycat中间件配置(端口8066):
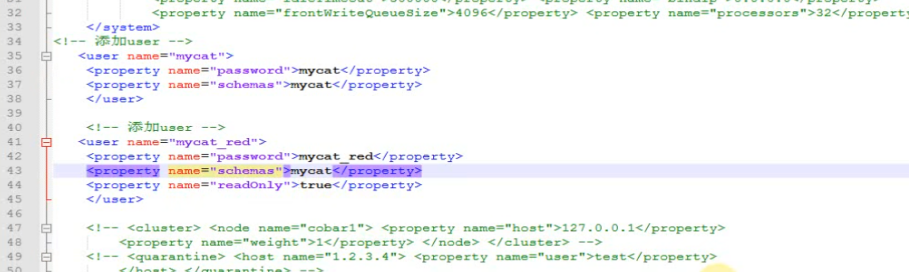
server.Xml中配置用户
配置schema.xml
配置rule.xml
1.1.6 .4 主从复制
原理:从机执行二进制可执行sql文件
***ps:***需要设置数据库允许远程访问(user表中root的host改为%,然后flush privileges;):
实现步骤
配置节点信息
主服务器修改配置文件,以Linux为例(etc/my.cnf),修改
server_id=id号,log-bin=mysql-bin从服务器修改配置文件中的
server_id=id号,log-bin=mysql-bin,binlog-do-db=数据库名
设置从服务器读取账号权限
主服务器设置从服务器权限(主服务器执行
GRANT REPLICATION SLAVE on *.* to 'mytest'@'%' IDENTIFIED BY '123456',根据实际情况,注意授权)主服务执行show master status得到File,Position等字段;
修改从服务器(
change master to master_host='192.168.85.141',master_user='mytest',master_password='123456',master_log_file='mysql-bin.000002',master_log_pos=608;)从服务器同步
start slave



